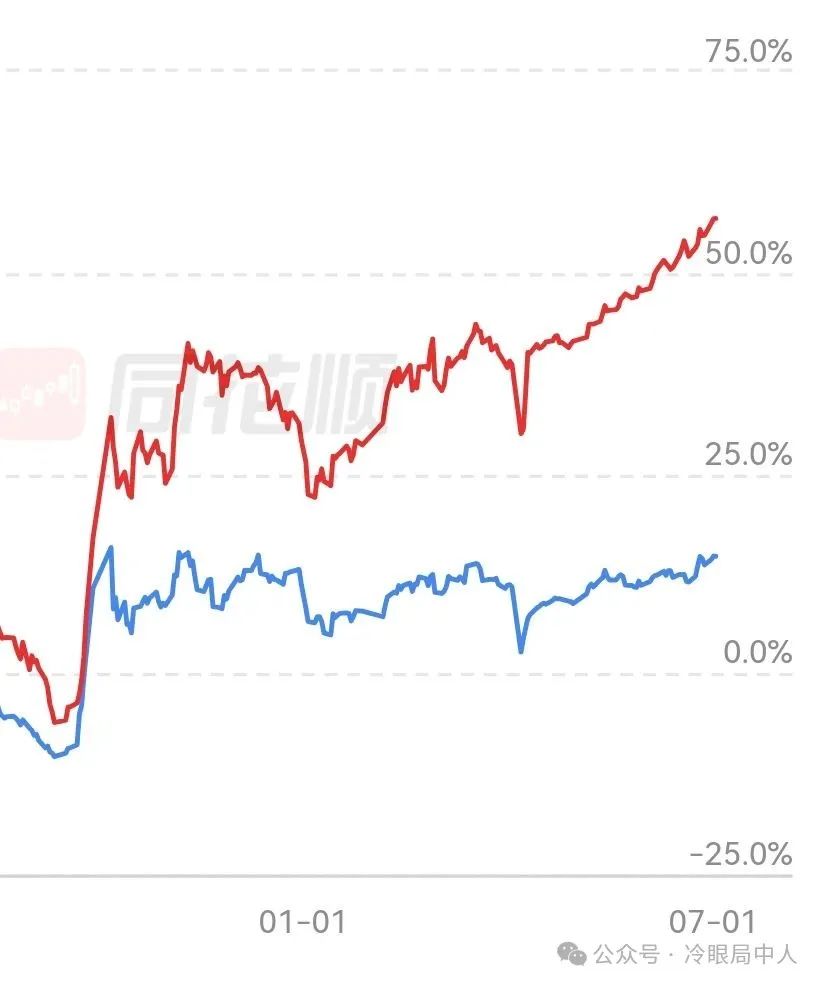
自从最近采取量化思维后,净值几乎天天新高,更可怕的是几乎已经没有回撤了,大家体会一下最近这个破曲线,彻底给我干麻了。越是这样,我就越感到无力与绝望。
时间回到2016年3月李世石与阿法狗的人机大战开启,在这场举世瞩目的较量中,人类第一被打的毫无招架之力,直接被干了3:0。
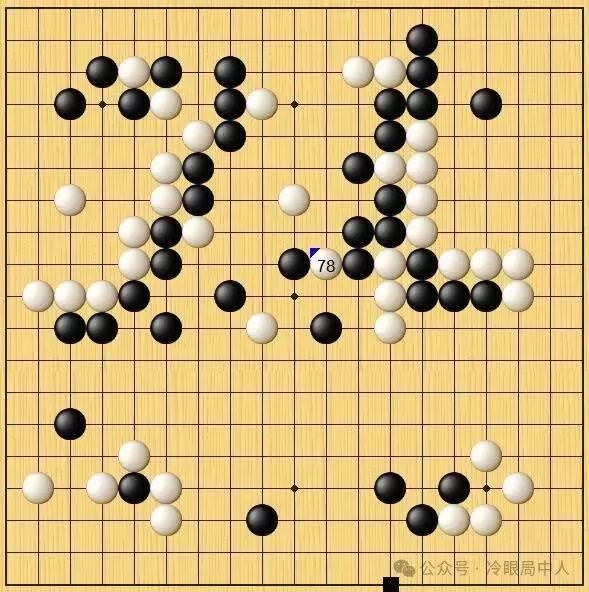
在接连三局负于“阿尔法围棋”后,脱去胜负包袱的李世石为荣誉而战,终于迎来了“人机大战”的首次胜利。在比赛进行到两个半小时后,李世石仅剩下17分钟,比“阿尔法围棋”剩余时间足足少1个小时。绝境中李世石祭出白78″挖”的惊天一手,一场“逆袭”之战也由此开始。AlphaGo被吓得陷入混乱,走出了黑93一步常理上的废棋,导致棋盘右侧一大片黑子“全死”。此后,“阿尔法围棋”判断局面对自己不利,每步耗时明显增长,首次被李世石拖入读秒。最终,李世石冷静收官锁定胜局。
在几大网络平台解说的嘉宾都赞不绝口,世界冠军古力甚至认为李世石这一手堪称:“神之一手”。当时观战的柯洁自信地说,他认为自己打败阿法狗的胜算有6-7成。但不成想,李世石这一手就是人类棋手最后的余晖。此后柯洁多次和阿法狗交手,最后被干的痛哭流涕。时间转眼过去了8年,现在围棋是什么场景呢?Ai已经不赖和人类棋手比赛了,因为完全不是一个层级,现在是顶尖棋手在比赛前都在学习ai之间对弈的棋谱。
有此感慨的原因是因为,最近看了一份美国银行研究部门2024年有关量化的300页的报告,差点给我看哭了。

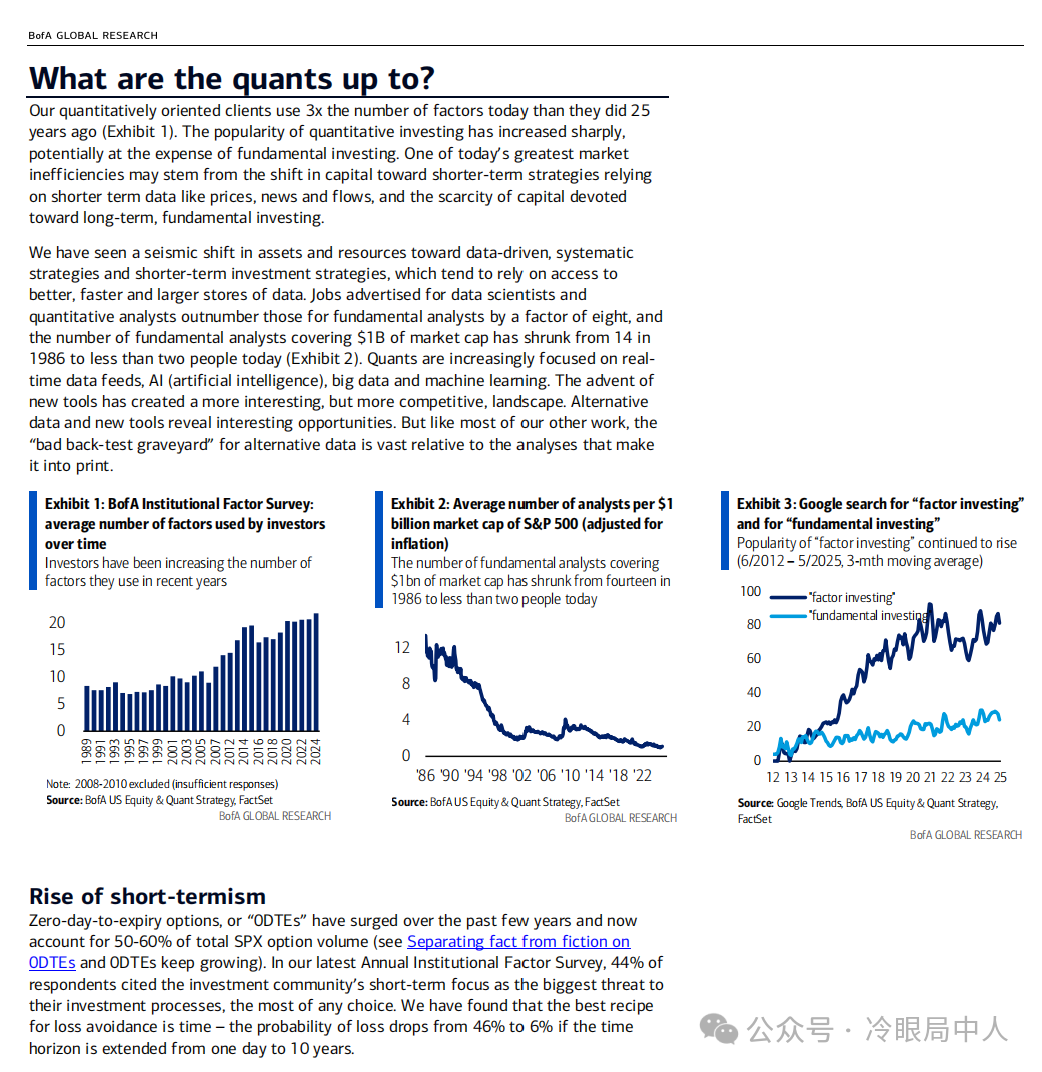
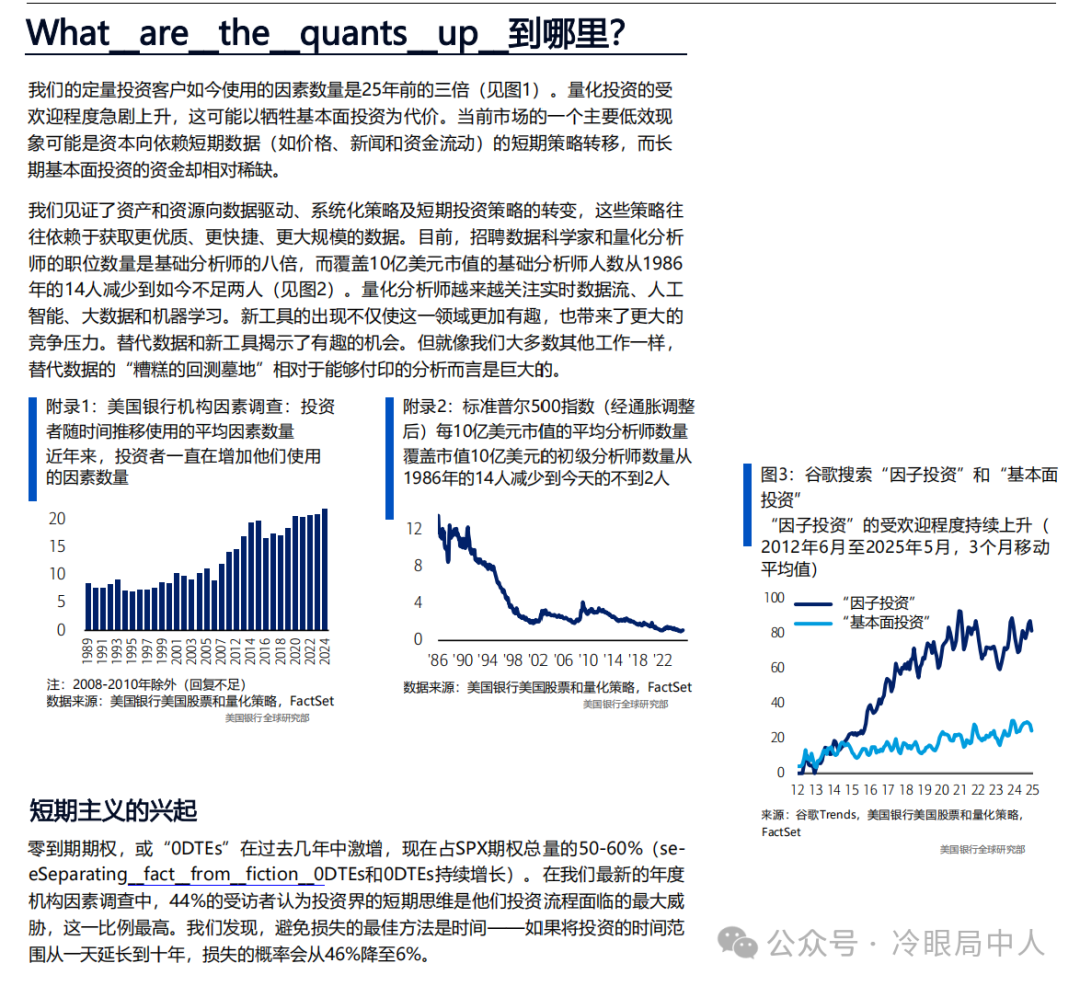
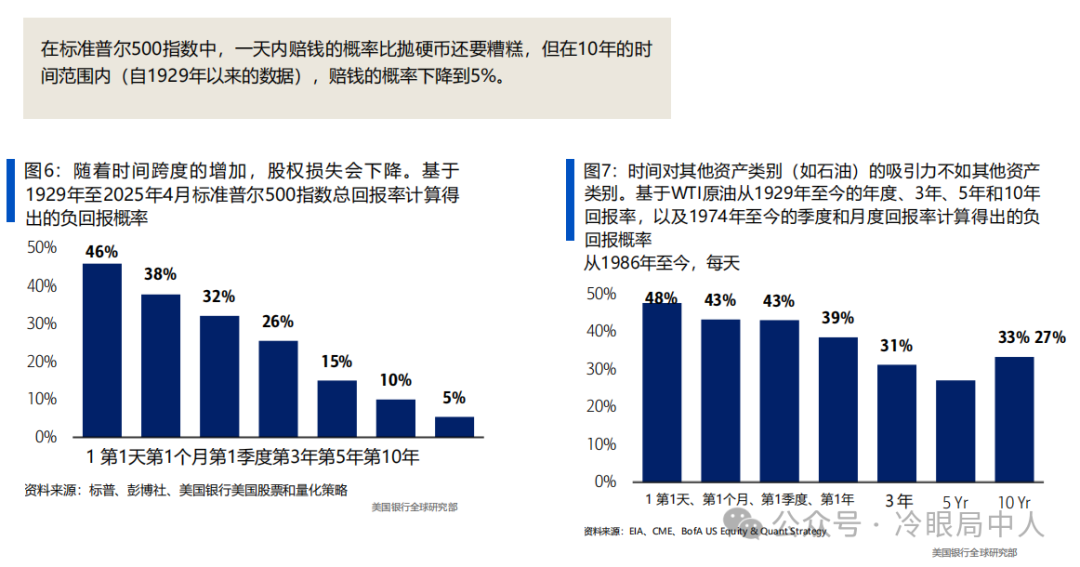
人类和量化的差距,我给你们只举一个例子,大家窥斑见豹:
例如在另类数据领域其中一个策略,NewsAlpha量化新闻对回报的影响。以前我也经常根据各种新闻做套利交易,收益也还不错。
新闻或许是最佳的替代数据集示例,它从全球多个语言的结构化和非结构化数据源中收集,能够成为回报的差异化因素。boa的分析显示,新闻中包含的信息似乎在短期内和长期内都能提供生成阿尔法的机会。
奈杰尔·塔珀利用Ravenpack的大数据集,量化了新闻对股价的影响。这一过程通过自然语言处理技术对与股票相关的新闻进行分类,并将这些新闻汇总成全球新闻脉动,以评估全球重要新闻的正面或负面趋势。在see__High Frequency__Monitor的回测期间,该模型与全球股市的相关性达到了79%。
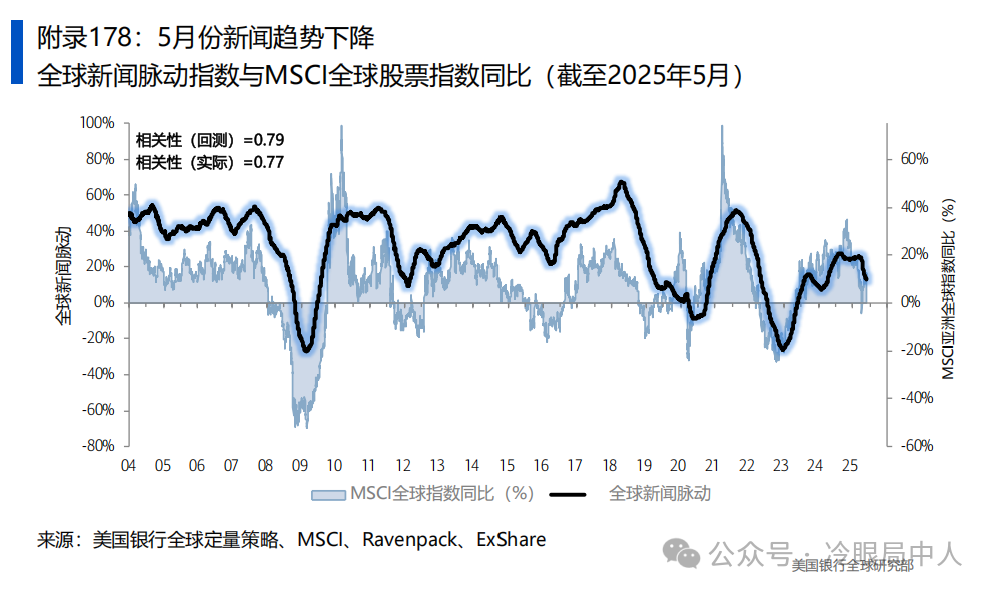
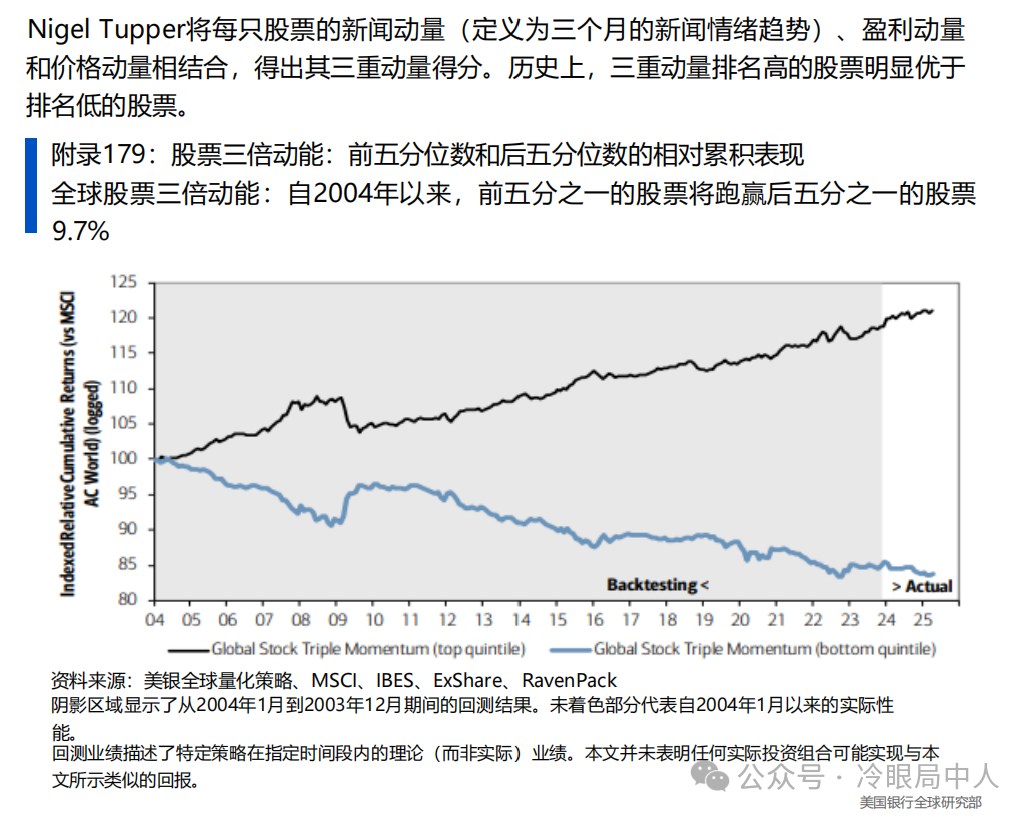
给你们解释一下Ravenpack的大数据集,就知道我为啥绝望了,这他妈都是什么样的对手啊:
RavenPack 的“大数据集”通常指的是他们的核心产品线之一:RavenPack Enterprise Datafeeds。这并不是一个单一的、固定大小的“文件”,而是一个持续更新、可定制、结构化的新闻和事件数据流,设计用于大规模的企业级应用,特别是金融市场的量化分析、交易策略、风险管理和研究。
你可以把它理解为:
核心:对海量全球新闻(文本)进行实时分析处理后生成的结构化量化数据。
目的:为机器(算法、模型)和专业人士提供标准化的、可计算的“新闻信号”。
以下是构成 RavenPack 大数据集的关键特征和内容:
1. 数据类型: 主要是情感 (Sentiment) 和 事件 (Events) 数据:
情感数据: 量化新闻对特定实体(公司、商品、指数等)情绪是积极、消极还是中性的。提供各种情感分数(复合分数、情感得分变化、新奇度等)。
事件数据: 识别和分类新闻中提到的具体事件(如:盈利公告、并购、管理层变动、产品发布、诉讼、自然灾害影响等),并为每个事件提供相关属性(参与者、地点、影响程度等)。
* 相关性得分: 衡量新闻与实体的相关程度。
* 新奇度指标: 判断该新闻信息是否为市场首次知晓。
* 新闻类别标签: 对新闻主题进行更细粒度的分类。
2. 数据源:
极其广泛: 涵盖全球数万家新闻来源,包括:
* 主流新闻通讯社 (如 Reuters, Bloomberg, Dow Jones)
* 专业财经媒体
* 区域和地方新闻媒体
* 行业和垂直领域出版物
* 有选择的网络新闻和博客
* 社交媒体(某些产品线提供)
* 监管文件(如EDGAR)
* 多语言覆盖: 处理多种语言的新闻,并通过其平台提供英文翻译和标准化。
3. 处理方式(这是其巨大价值所在):
* 自然语言处理 (NLP) 和机器学习 (ML): 使用先进的算法自动分析每篇新闻的文本。
* 实体识别 (Named Entity Recognition – NER): 准确识别新闻中提到的公司、人员、地点、产品、指数等。
* 事件检测与分类: 自动识别新闻中描述的事件类型并分类。
* 情感分析: 量化文本对特定实体的情感倾向。
* 标准化和结构化: 将非结构化的文本转化为标准化的、包含时间戳的、机器可读的数据记录。
4. 覆盖范围:
* 实体覆盖: 数百万家上市公司、非上市公司、政府机构、地缘政治实体、货币、商品、指数等。通常链接到标准金融标识符(如 RIC, ISIN, CUSIP, FIGI, SEDOL 等)。
* 时间覆盖:
* 实时数据流: 毫秒级延迟推送。
* 深厚的历史数据: 通常提供超过 20 年(自2000年起)的历史数据存档,对于回测交易策略至关重要。
5. 格式与交付:
* API 流: 实时获取数据流。
* 批量文件下载: 以CSV或其他标准格式下载历史数据或每日增量数据。
* 高频率更新: 每秒可能有数百甚至数千条新记录产生。
* 可定制化: 客户可以根据需要选择特定的数据字段、实体、事件类型、来源、地理区域等来订阅数据流,过滤掉不相关的信息。
6. 目标用户与应用场景:
* 对冲基金、投资银行、资产管理公司: 开发量化交易策略(新闻驱动交易)、因子投资、风险建模、投资组合监控。例如,基于负面新闻情绪做空,或基于并购公告做多。
* 企业情报与风险管理: 监控公司声誉、品牌风险、供应链风险、地缘政治风险、同行竞争对手动向。
* 卖方研究机构: 为客户提供基于另类数据的研究洞察。比如发现未被广泛报道的公司基本面变化趋势。
* 监管科技: 监控市场滥用行为或检测潜在的内幕交易信号。
总结来说,RavenPack 的大数据集 (Enterprise Datafeeds) 是:
一个全球新闻和事件的实时、历史、结构化、机器可读的量化数据库。它利用NLP/ML技术将海量非结构化文本转化为可直接输入算法和分析模型的情感分数、事件标识符和实体关联数据,为金融和其他行业的专业人士提供可操作的另类数据洞察。
它区别于其 News Analytics Platform(更侧重于交互式网络平台查询)和 Dow Jones Edition(与道琼斯新闻深度整合的特定产品),是整个RavenPack产品生态中最基础、最灵活、最适合大规模处理和建模需求的数据产品。如果你管理着一个大型对冲基金的量化交易系统,这很可能就是你接入RavenPack的方式——通过API直接输入到你的交易算法中。
以下是关键特点和内容:
1. 核心数据: 全球新闻的情感分析和事件识别
* 情感数据: 量化新闻对实体的积极/消极情绪 (提供多维分数)。
* 事件数据: 识别新闻中的具体事件类型(如盈利公告、并购、产品发布、诉讼等)。
* 实体关联: 精准链接到公司、商品、指数等 (使用标准金融标识符如RIC, ISIN等)。
* 相关性、新奇度等指标: 衡量新闻重要性。
2. 数据源覆盖广:
* 全球数万家主流新闻社、财经媒体、专业期刊、网站及部分社交媒体/监管文件。
* 多语言处理能力。
3. 强大处理技术:
* 利用 NLP 和 机器学习 自动分析文本。
* 识别实体、检测事件类型、量化情感、标注分类。
* 将非结构化文本转化为标准化、机器可读的数据记录。
4. 覆盖规模大:
* 实体:数百万家公司、政府机构、商品等。
* 时间:提供实时数据流(毫秒级延迟)和深度历史数据(通常自2000年起)。
* 频率:每秒可能产生数百至数千条记录。
5. 交付方式灵活:
* API 流(实时)
* 批量文件下载(历史/增量数据)
* 高度可定制:可按字段、实体、事件类型、来源、地区等筛选。
6. 典型应用场景:
* 量化交易:新闻情绪驱动策略(如情绪突变时自动交易)。
* 风险管理:实时监控公司声誉、供应链风险。
* 投资研究:发现未公开的基本面变化或事件信号。
* 监管合规:监测市场违规行为。
这还是量化交易非常细小的一个分支领域,所以大家现在能体会到绝望了吗?李世石在当年下出了惊天的78手,在今年7月底到8月,Bruce也将开启自己A股交易生涯的最后一战,到明年中我就该退休了。请各位欣赏人类顶级策略师的最后余晖(可以毫不客气的说,在策略领域除了已故的金涛总外,Bruce谁都不服。也就是哥没有干这行,否则新财富那啥的,呵呵你们懂的),但是现在都没有意义了,以后我就转型做ai策略解说员得了。
下个月开始我将给各家机构,开始系列讲解世界量化策略的最新进展与配置思路:

有机生命的光辉并不会消亡,它只是会用另一种形式悄悄绽放,重生。
P.S大家还记得去年说的叹息之墙吗,还记得想突破叹息之墙得靠啥啊?
发表回复